Sponsors












Web scraping with Selenium
There comes a time in the life of every programmer when they come to the realization that they in fact need to start web scraping! But hey, it’s not all about spamming, identity theft, and automated bot attacks—web scraping can have totally legitimate applications these days like R&D, data analysis, and much more. So give yourself a Python refresher and dive in with us as we look at Selenium.
Selenium is a free automated testing suite for web applications and we can use it to mine data from any website. Here are the simple steps to write the script for scraping data from any website using Selenium.
Installing Selenium
-
Install pip on your system
Download the get-pip.py . Then run it from the command prompt.
$ python get-pip.py-
Install selenium python package using pip
$ pip install selenium-
Install web drivers to emulate the browsers
You can download any (firefox/chrome/Edge) webdriver from this websites. We need the driver because selenium uses the web browser to scrape the data from the websites.
https://sites.google.com/a/chromium.org/chromedriver/downloads
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
https://github.com/mozilla/geckodriver/releases
-
Make driver executable available globally
Next step is put this driver executable in $PATH variable so it can be used from anywhere. To do so execute this command in terminal,
For MAC/Linux user,
"export PATH=$PATH:path/to/webdriver" >> $HOME/.bash_profile
For Windows user,
Go to Environment variables, and put webdriver path in PATH variable. To do so follow this steps.
- Right click on My Computer.
- Click on Properties.
- Click on Advanced System Settings which will open a pop up box.
- Click on Environment variables.
- Click on PATH on the top window and then click on Path on the bottom window as shown in figure above.
- Add your driver executable path there.
Web scraping using Selenium
We will be scraping data from http://www.phptravels.net/ for our example. This is a test website from which we can extract data for this tutorial.
Now, the first step is to load the webdriver which we downloaded before. I will be using chrome webdriver for this example but you can use the same procedure for other web drivers.
import selenium
from selenium import webdriver
driver = webdriver.Chrome()
time.sleep(5)
driver.quit()This code snippet will just load the chrome webdriver instance, wait till the 5 seconds are up, and the quit. But this isn’t what we wanted, we want to scrape the data from the website. So let’s get started with it.
import selenium
from selenium import webdriver
url = "http://www.phptravels.net/login"
driver = webdriver.Chrome()
if __name__ == "__main__":
driver.get(url)
driver.wait(5)
driver.quit()This will lead you to the login page of this website. Now, you have to enter a username and password in the textboxes. This you can do this automatically using selenium’s send_keys() method.
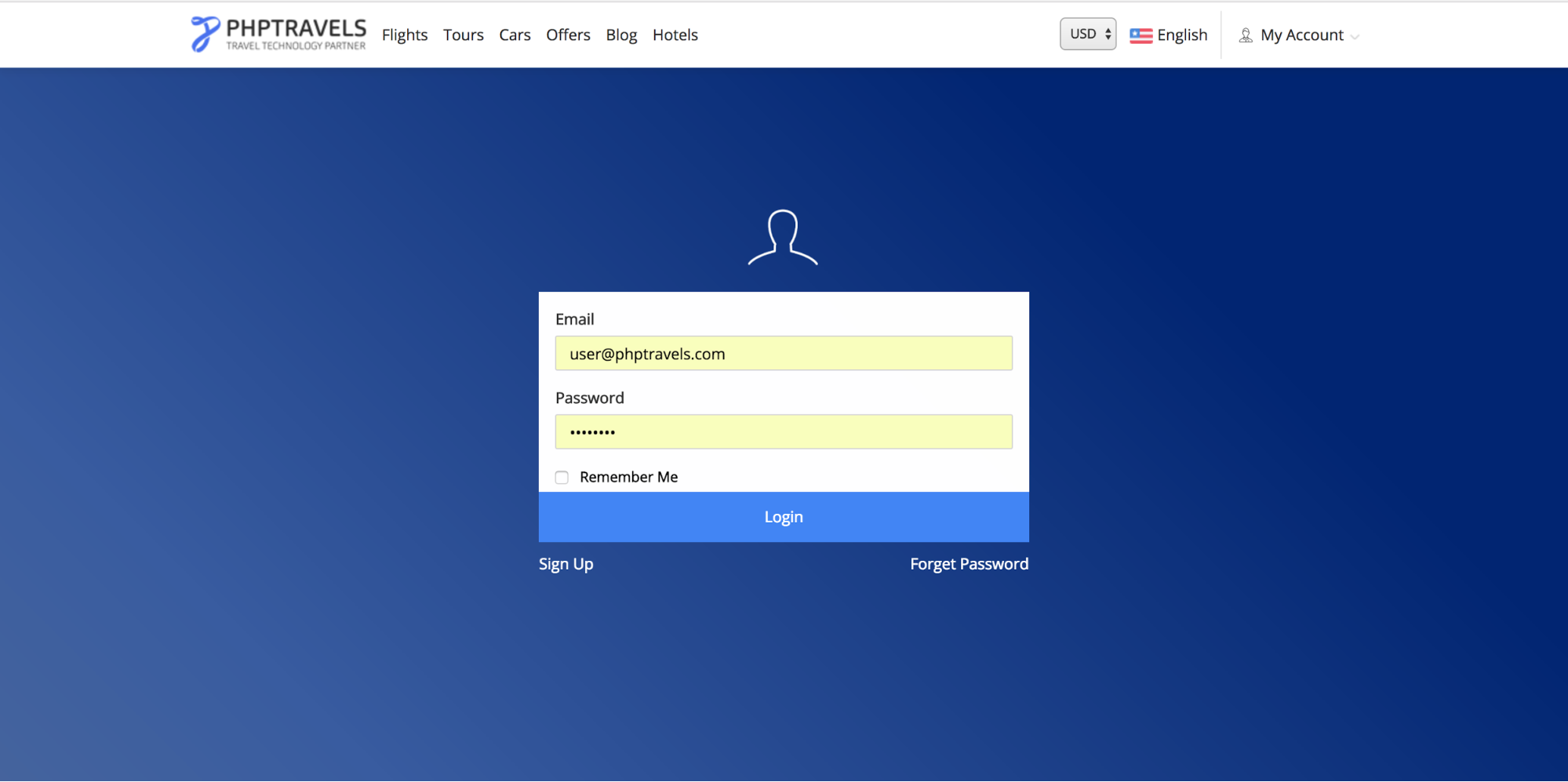
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
url = "http://www.phptravels.net/login"
username = "user@phptravels.com"
password = "demouser"
driver = webdriver.Chrome()
if __name__ == "__main__":
driver.get(url)
uname = driver.find_element_by_name("username") ← find by element name
uname.send_keys(username) ← enters the username in textbox
passw = driver.find_element_by_name("password")
passw.send_keys(password) ← enters the password in textbox
# Find the submit button using class name and click on it.
submit_button = driver.find_element_by_class_name("loginbtn").click()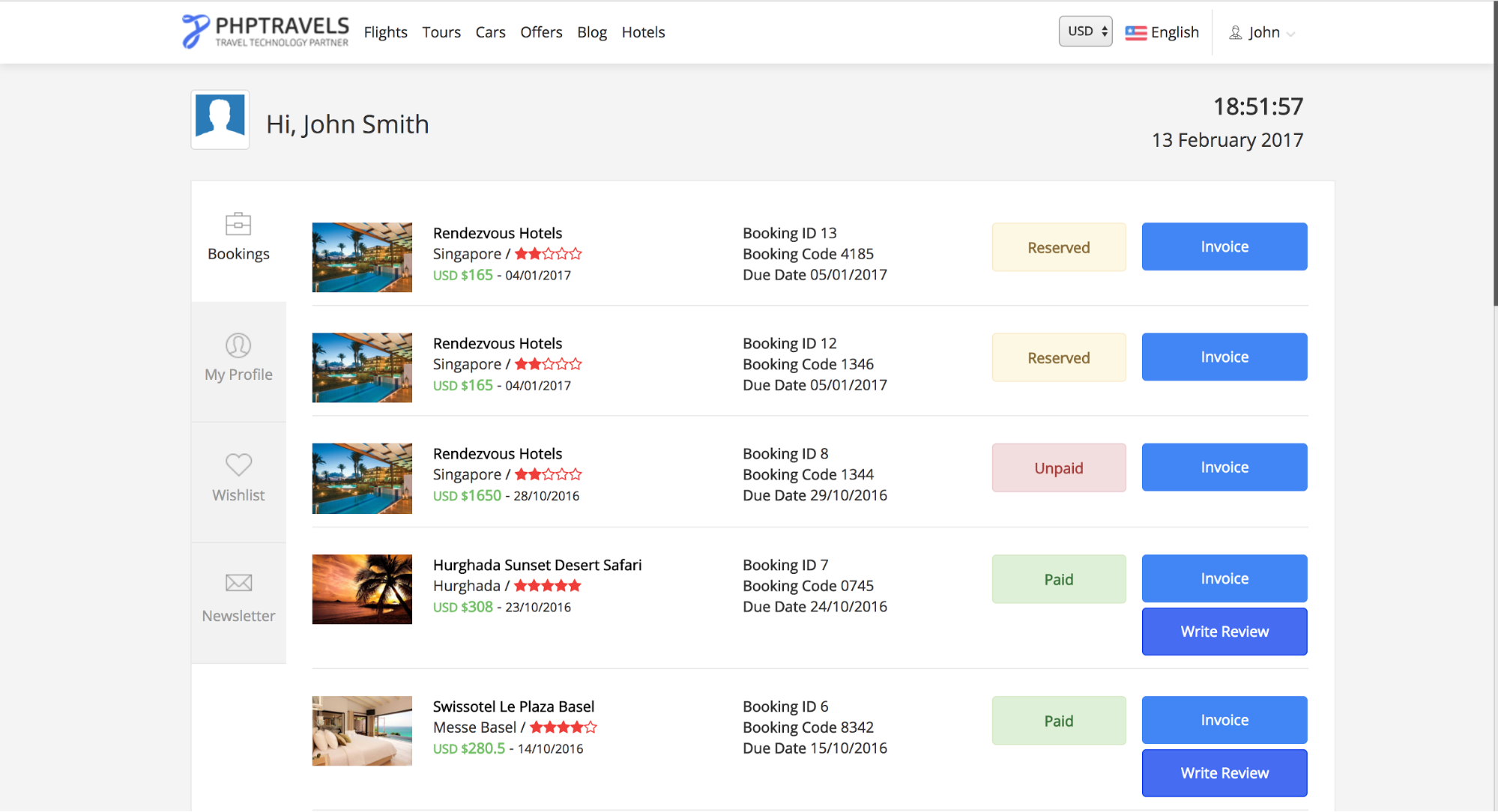
When the driver clicks on the submit button, the browser will redirect to the above webpage. And now we will scrape the data from this page.
We can find all the information related to input field name, id, classname, text from the page source or inspect element tab of the browser. For example, the submit button on this page doesn’t have any id or name so we used class name “loginbtn” to find the element. Here is the list of all these methods [To find the elements from the page].
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- Find_element_by_css_selector
Now our next job is to collect information from this webpage. We can get all the bookings related data for this user using this web page information. We will collect all the hotel names which are booked by this user. To scrape the data, add this code to your script.
WebDriverWait(driver, 100).until( lambda driver: driver.find_element_by_id('bookings'))
divs = driver.find_element_by_id("bookings")
rows = divs.find_elements_by_class_name("row")
print '-----------------------------------------------------'
for row in rows:
name = row.find_element_by_tag_name('a')
print name.text
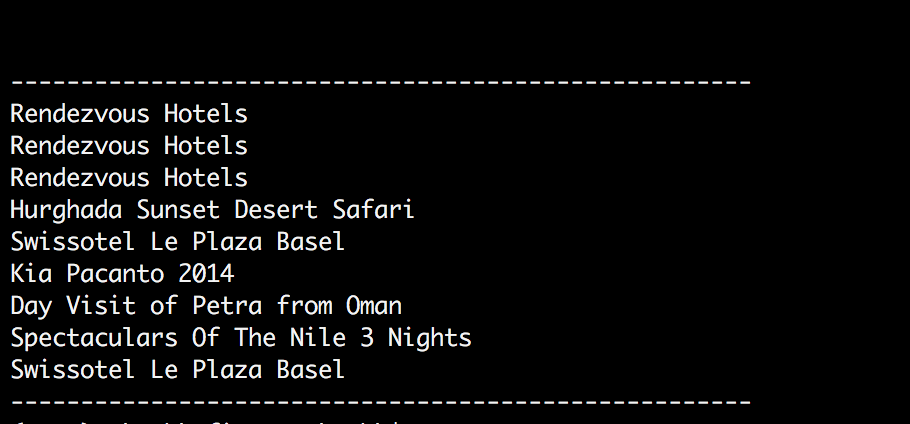
print '-----------------------------------------------------' Now, we want the text “Rendezvous Hotels” from this page source. The first line of this code snippet will make the web driver wait until the page is fully loaded and able to find the “bookings” id. Then we will find all the rows inside the “bookings” div. Now our text is inside the anchor tag so we will iterate through all the rows and find the links inside each div. Here is the output of whole code snippet.
Now, we want the text “Rendezvous Hotels” from this page source. The first line of this code snippet will make the web driver wait until the page is fully loaded and able to find the “bookings” id. Then we will find all the rows inside the “bookings” div. Now our text is inside the anchor tag so we will iterate through all the rows and find the links inside each div. Here is the output of whole code snippet.
 This way you can get all the information which is on the page. You can navigate to other web pages using selenium’s webdriver to get other related information. You can store this data in Excel or in any database according to your need.
This way you can get all the information which is on the page. You can navigate to other web pages using selenium’s webdriver to get other related information. You can store this data in Excel or in any database according to your need.
Here are the some other details about Selenium web driver which you can use in your web scraper to mine the data in an efficient manner.
Action Chains
Action chains can be used to automate some low level movements on the web page such as mouse movements, mouse button actions(left/right click) and context menu interactions. This can be very useful for performing some actions like mouse hover and drag & drop.
Example:
Class Name : selenium.webdriver.common.action_chains.ActionChains(driver)
menu = driver.find_element_by_css_selector(".nav")
hidden_submenu = driver.find_element_by_css_selector(".nav #submenu1")
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()In this example, the chain of action is being performed to click on hidden submenu of navigation bar. The first two lines will locate the element which we want to use in action chain, in this case a hidden submenu. When you run this code snippet, first the mouse cursor will move to the menu bar and then it will click on hidden submenu.
These are the methods which can be used in action chain.
- click() → Clicks an element
- click_and_hold() → Holds down the left mouse button on an element.
- context_click() → Right click on the element.
- double_click() → Double click on the element.
- move_to_element() → Move mouse to middle of an element.
- key_up() → Send a keypress (only Control, Shift and Alt).
- key_down() → Release a key press.
- perform() → Performs all stored actions.
- send_keys() → Send keys to current focused element.
- release() → Release held mouse button on element.
Webdriver Exceptions
Here is the list of exceptions that may happen in your code while using selenium web driver.
- selenium.common.exceptions.ElementNotSelectableException()
- selenium.common.exceptions.ElementNotVisibleException()
- selenium.common.exceptions.ErrorInResponseException
- selenium.common.exceptions.ImeActivationFailedException
- selenium.common.exceptions.NoSuchAttributeException
- selenium.common.exceptions.NoSuchElementException
- selenium.common.exceptions.TimeoutException
- selenium.common.exceptions.UnexpectedTagNameException
Locating the elements
Here is the list of attributes which can be used to locate any elements on the web page.
Classs Name : selenium.webdriver.common.by.By
CLASS_NAME= 'class name'
CSS_SELECTOR= 'css selector'
ID= 'id'
LINK_TEXT= 'link text'
NAME= 'name'
PARTIAL_LINK_TEXT= 'partial link text'
TAG_NAME= 'tag name'
XPATH= 'xpath'
Alerts using Selenium Webdriver
Class Name : selenium.webdriver.common.alert.Alert(driver)
Alert(driver).accept() → Accepts the alert available
Alert(driver).dismiss() → Dismisses the alert available
Alert(driver).authenticate(username, password) → Sends uname/pass to dialog
Alert(driver).send_keys(keysToSend) → Send keys to alert
Alert(driver).text() → Get the text from alertSo there you have it—a brief introduction to web scraping with Selenium. Now just remember to use your newfound power for good!
Recent Stories


Top DiscoverSDK Experts



Featured Products

Compare Products
Select up to three two products to compare by clicking on the compare icon () of each product.
{{compareToolModel.Error}}
{{CommentsModel.TotalCount}} Comments
Your Comment