Sponsors












Introduction to Mongo DB
In this article, we will have a look at integrating MongoDB, a very popular NoSQL open source database. We will study basic MongoDB operations on command line shell.
MongoDB is written in C++, with many great features like map-reduce, auto sharding, replication, high availability etc.
MongoDB
MongoDB is an open-source database developed by MongoDB Inc. Key points to notice about how MongoDB works are:
- It stores data in JSON-like documents that can vary in structure.
- MongoDB uses dynamic schemas, which means that we can create records without first defining the structure of the fields of their types.
- Structure of a record can be changed simply by adding new fields or deleting existing ones.
The mentioned data model gives us the ability to represent hierarchical relationships, to store arrays, and other more complex structures easily.
Terminologies
Understanding concepts in MongoDB becomes easier if we can relate them to relational database structures. Let's see the close analogy Mongo follows with traditional MySQL system:
-
Database is a physical container for collections. Each database gets its own set of files on the file system. A single MongoDB server typically has multiple databases.
- Table in MySQL becomes a Collection in Mongo. Documents within a collection can have different fields. Typically, all documents in a collection are of similar or related purpose.
- Rows becomes Document and is a set of key-value pairs. Documents have dynamic schema.
- Columns becomes Fields.
- Joins are termed as linking and embedded documents.
Advantages of MongoDB over RDBMS
-
MongoDB is a schema-less type of database. Single databases can have many documents with different fields.
- Structure of a single object is simple and clear.
- No Joins.
- MongoDB is easy to scale.
- Conversion/mapping of application objects to database objects not needed.
- Uses internal memory for storing the (windowed) working set, enabling faster access of data.
Auto-sharding in MongoDB
Sharding is just another name for "horizontal partitioning" of a database.
In Horizontal partitioning, rows of a database table are held separately, rather than splitting by columns. Each partition forms part of a shard, which may in turn be located on a separate database server or physical location. The advantage is the number of rows in each table is reduced which reduces index size, thus improving search performance.
Collection Group Documents
Collections are simply groups of documents. Since documents exist independently, they can have different fields.
For example, let’s suppose 3 Book documents which are part of a common Books collection:

As shown in the table above, 3 Book documents have different fields and they can still exist in a single collection.
How to interact with MongoDB shell?
We can start the MongoDB through the terminal application. Follow the official MongoDB documentation for installation instructions.
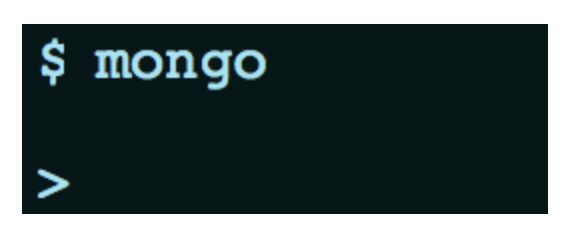
Simply type mongo, as shown in above image.
All instances of MongoDB come with a command line program we can use to interact with our database using JavaScript.
Once the command line is open, try simple Javascript variable as:
> var potion = {
"name": "Harry Potter",
"vendor": "BlackSim"
}If you type potion in the terminal, you will get back what you expect normally,
{
"name": "Harry Potter",
"vendor": "BlackSim"
}As clearly seen, documents are just JSON-like objects.
MongoDB comes with helper methods to make it easy to interact with the database.
Creating a database
Now, let’s start using a database. It is interesting to note that if you switch to a database which doesn’t exist yet, MongoDB will create that for you.
So, following command will create a Database called ‘student’ for you:
> use student
Now when you ask for a ‘db’, you will get back ‘student’.
Creating a collection and document
Let’s move forward by creating a collection and inserting document into it.
Once you execute below command in shell:
> db.books.insert(
{
"name": "Harry Potter",
"vendor": "BlackSim"
}
)As ‘books’ collection doesn’t exist yet, it will be created and a new document will be inserted into it. The output you will get back once you execute above command will look like:
WriteResult({ "nInserted": 1 })
Whenever we write to the database, we’ll always be returned a WriteResult object that tells us if the operation was successful or not. ‘1’ means that a single documents was inserted.
Finding all books
To run a search, we need yet another simple command as shown:
> db.books.find()
As a result, we will get back:
{
"name": "Harry Potter",
"vendor": "BlackSim"
}Let’s add two more books,
> db.books.insert(
"name": "Blood Prince",
"price": 3.99
}
)
> db.books.insert(
{
"name": "Order of Phoenix",
"vendor": "BlackSim",
"standard": "Difficult"
}
)Let’s run a search again using:
> db.books.find()
Result will be:
{ "name": "Harry Potter", … }
{ "name": "Blood Prince", … }
{ "name": "Order of Phoenix", … }Object IDs make documents unique
Every document is required to have a unique _id field. If we don’t specify one when inserting a document, MongoDB will generate one using the ObjectId data type.
When we actually run a command like:
> db.books.find()
We will get back:
{
"_id": ObjectId("663f78d741894edebdd8cc7q"),
"name": "Harry Potter",
"vendor": "BlackSim"
}It’s common to let MongoDB to handle _id generation.
Finding a Specific Book With a Query
We can perform a query of equality by specifying a field to query and the value we’d like. Let’s run the find() command:
> db.potions.find({"name": "Harry Potter"})
As expected, we will get back our book back:
{
"_id": ObjectId("663f78d741894edebdd8cc7q"),
"name": "Harry Potter",
"vendor": "BlackSim"
}>>> Queries will return all the fields of matching documents.
Queries That Return Multiple Values
We can also get multiple values, just normally if they match. Let’s run the find() command again, with a different parameter:
> db.potions.find({"vendor": "BlackSim"})
Clearly, we have more than one match. Output will be:
{
"_id": ObjectId("663f78d741894edebdd8cc7q"),
"name": "Harry Potter",
"vendor": "BlackSim"
}
{
"_id": ObjectId("663f78d741894edebdd8cc7q"),
"name": "Order of Phoenix",
"vendor": "BlackSim",
"standard": "Difficult"
}
What else, apart from JSON objects, can we store?
MongoDB represents JSON documents in binary-encoded format called BSON behind the scenes. BSON extends the JSON model to provide additional data types, ordered fields, and to be efficient for encoding and decoding within different languages.
BSON was designed to have the following three characteristics:
- Lightweight Keeping spatial overhead to a minimum is important for any data representation format, especially when used over the network.
- Traversable BSON is designed to be traversed easily. This is a vital property in its role as the primary data representation for MongoDB.
- Efficient Encoding data to BSON and decoding from BSON can be performed very quickly in most languages due to the use of C data types.
Conclusion
Our initial guide to MongoDB ends here. We will continue our tutorial with a deeper understanding of type of data you can store, deletion, embedded documents and much more in MongoDB tutorial: Part 2.
I hope you enjoyed this tutorial. Wait to read more !
Recent Stories


Top DiscoverSDK Experts



Featured Products
Compare Products
Select up to three two products to compare by clicking on the compare icon () of each product.
{{compareToolModel.Error}}
{{CommentsModel.TotalCount}} Comments
Your Comment