Sponsors












Git Rebase vs Git Merge

In our last article, we learned about git pull which helps us import all the changes from a remote branch to our local machine. For instance, say we created some branch that split from the develop branch, continued to code and code in it, and then we want to merge it back to develop. How do we do this? First, we need to be sure that there won’t be conflicts with develop (for example if another developer made changes to develop on the same files that we worked on). How to check? We run pull (which automatically does a merge) with the branch we want to merge with.
The process is as follows:
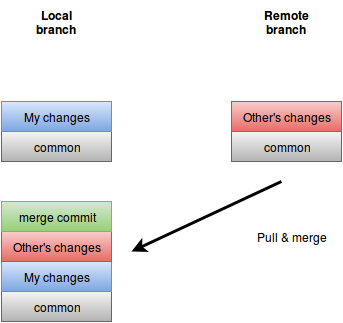
The pull process takes the changes that were made in the remote server, puts them in my server and creates a merge—even if there aren’t any conflicts, which is an important point. If there are conflicts, I need to resolve them, push the changes back to my local branch, and then make a pull request.
That’s all well and good, but the problem is if we’re working as part of a large team, because of all the unnecessary merges, the log will start to get cluttered with countless unnecessary merge entries. In order to prevent this kind situation, there exists a slightly different process from merge called rebase. And how does Git Rebase work? Well it goes like this:
First, it does a rollback to all the changes that I made on the local version. Then it goes to the version I want to merge with and starts to push all the changes that occurred in it, one after the other. When it runs into one of my commits it adds it to all the changes. If I have several commits, it adds them according to the time they were entered. In other words, it’s as if I pushed my code after each change. It looks a little something like this:
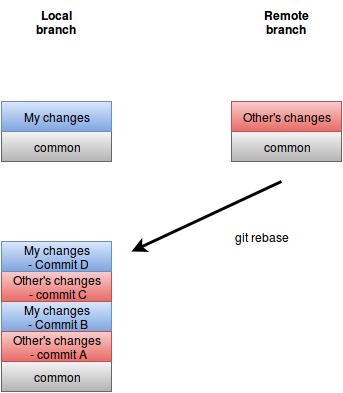
So rebase does a rollback to the point in time where the merge occurred. It takes the first commit chronologically and puts it in. Then takes the second puts in on the first, and so on until it finishes. If there are conflicts, the process is stopped and the user must resolve them. Only then will the process start again. Once all the commits both remote and local are finished, only then is the rebase complete and you can open a pull request.
From a technical point of view we do it like this:
git rebase origin develop
And if there are conflicts, you have to resolve them and then run:
git rebase --continue
And if you’re getting frustrated and you want to go back to how it was before you started the rebase, then run:
git rebase --abort
After everything is ready to go, run commit with all the changes and then open a pull request.
When to use rebase
The rebase process seems confusing and even a bit scary once you understand that the process includes a rollback of the changes and putting them back again in chronological order according to commits made on the remote server. But it’s really worthwhile to use it because if you use pull each time, especially in a large team, the log will get real messy.
When to not use rebase
It’s a good idea to not use rebase on branches that other people have access to. What do we mean by this? If it’s my local branch that only I work on, great, use it. But if it’s a branch that other people are working on, rebase is likely to cause trouble because it changes the actual history of the branch. If there’s someone else that works on that branch, the fact that I changed their history can destroy their work and cause never-ending conflicts for them.
In the next article, we’ll take a look at a live example using Git with real code. Stay tuned!
About the author: Ran Bar-Zik is an experienced web developer whose personal blog, Internet Israel, features articles and guides on Node.js, MongoDB, Git, SASS, jQuery, HTML 5, MySQL, and more. Translation of the original article by Aaron Raizen.
Recent Stories


Top DiscoverSDK Experts



Featured Products


Compare Products
Select up to three two products to compare by clicking on the compare icon () of each product.
0 Comments
Your Comment